2023-beging(项目)
一
面试总结–(一面)
讲一下图谱可视化分析项目是什么?
图谱可视化分析项目是指将大规模、复杂的数据转化成图谱形式,并通过可视化的方式展示出来,以便人们更好地理解和分析这些数据。这种项目通常需要使用数据挖掘、机器学习、自然语言处理等技术来将数据进行处理和转化,最终生成可视化图谱。
图谱是一种以节点和边为基础构建的数据结构,节点代表实体或概念,边表示实体或概念之间的关系。图谱可视化分析项目通过将数据转化成节点和边的形式,可以更直观地展现出数据之间的关系,以及它们的属性和特征。这种展示方式可以帮助人们发现数据中的规律和趋势,支持数据驱动的决策和分析。
图谱可视化分析项目可以应用于各种领域,例如金融、医疗、社交网络等。在金融领域,图谱可视化分析可以用于检测欺诈行为和风险分析;在医疗领域,可以用于疾病诊断和药物发现;在社交网络领域,可以用于社交网络分析和影响力分析等。
总之,图谱可视化分析项目是一种将大规模、复杂的数据通过图谱形式展示出来的技术,可以帮助人们更好地理解和分析数据,发现数据中的规律和趋势,支持数据驱动的决策和分析。
d3js和echarts的区别
d3.js和ECharts都是用于可视化数据的JavaScript库,但是它们有以下几点区别:
功能和用途不同:d3.js是一个数据驱动的JavaScript库,用于创建动态交互式数据可视化。ECharts则是专注于图表可视化的库,提供了一系列内置的图表类型,如折线图、柱状图、饼图等。
数据绑定方式不同:d3.js的核心理念是数据绑定,即将数据与DOM元素绑定,然后通过操作数据来控制DOM元素。而ECharts则是通过设置选项来配置图表的样式和数据。
API和使用方式不同:d3.js的API相对更为底层,需要开发者手动进行DOM操作和动画效果的编写。而ECharts则提供了更多的封装,通过简单的配置选项即可生成丰富的图表,也提供了更多的交互和动画效果。
社区支持不同:d3.js是由Mike Bostock等人创建的开源项目,拥有庞大的社区和活跃的开发者,有丰富的示例和文档资源。ECharts则是由百度开发并维护的项目,拥有庞大的用户群体和活跃的社区,也有丰富的文档和示例资源。
总的来说,d3.js更加灵活和自由,适用于开发者需要高度自定义的数据可视化场景,而ECharts则更加便捷和高效,适用于快速构建各种类型的图表。
d3js是操作svg吗
d3.js是一个JavaScript库,它可以用于操作HTML文档中的各种元素,包括SVG元素和HTML元素。它最初是为了操作SVG(Scalable Vector Graphics,可缩放矢量图形)而创建的,但现在它也可以用于操作HTML元素。因此,d3.js可以用于创建和操作各种图形,包括线条、圆形、矩形、文字、路径、饼图、力导向图等等。它具有强大的数据绑定和动画功能,可以使数据可视化的开发更加简单和高效。
d3js可以操作canvas吗
虽然d3.js最初是为了操作SVG而创建的,但它也可以用于操作HTML5中的canvas元素。HTML5的canvas元素提供了一种使用JavaScript绘制图形和动画的方式,它比SVG更适合于处理大量数据或高度动态的图形。d3.js提供了一些方法来在canvas上绘制基本的图形,如矩形、圆形、线条等,以及提供了一些布局算法和数据绑定功能,可以帮助我们在canvas上创建数据可视化。但需要注意的是,d3.js在canvas上的表现和在SVG上不同,需要针对canvas元素做出一些特殊的处理和适应。
负责http请求的axios封装 (这一块是怎么做的能讲一下吗)
在项目中进行axios的封装可以提高代码的复用性和可维护性,可以在多个地方引用相同的axios实例,也可以通过拦截器对请求和响应进行统一处理,以减少代码的重复性。
以下是一个示例axios封装的具体步骤:
在项目中创建一个单独的文件,例如http.js,用于封装axios请求。
在http.js中引入axios,并创建一个新的axios实例:
1 | |
在创建axios实例时,可以设置一些默认参数,例如基础URL、超时时间和请求头信息等,这些参数将应用于所有使用该实例发出的请求。
在其他组件或模块中引入封装好的axios实例,并使用它发送请求。例如:
1 | |
在这个示例中,我们使用了在http.js中创建的axios实例,发送了一个GET请求,如果请求成功,则输出响应数据;如果请求失败,则输出错误信息。
通过这种方式进行封装,我们可以在整个项目中使用相同的axios实例,避免了在每个组件或模块中重复地创建实例,同时可以在请求拦截器和响应拦截器中对请求和响应进行统一处理,提高了代码的可维护性和可读性。
中断取消请求是怎么做的
在axios中,中断/取消请求可以通过使用CancelToken实现。CancelToken是axios提供的一个构造函数,它可以用来创建一个取消请求的令牌。当一个请求被取消时,我们可以使用该令牌来通知axios取消该请求。
以下是一个示例:
1 | |
在这个示例中,我们创建了一个取消请求的令牌,将该令牌传递给请求的配置对象中的cancelToken属性中。当需要取消请求时,我们调用source.cancel()方法,并传入一个取消请求的原因,这个原因将被传递给请求的catch函数。
当请求被取消时,catch函数将捕获到一个带有message属性的错误对象,我们可以通过判断该错误是否是一个取消请求的错误来处理请求被取消的情况。
需要注意的是,一旦请求被取消,axios将不再执行then函数,而是直接跳转到catch函数。此外,使用CancelToken取消请求的前提是该请求必须是可取消的,即该请求必须是一个异步请求,不能是同步请求。
大文件上传,使用切片上传形式,支持上传、暂停、续传
大文件长传并发的怎么确保后端接收的顺序
另外由于是并发,传输到服务端的顺序可能会发生变化,因此我们还需要给每个切片记录顺序
在生成文件切片时,需要给每个切片一个标识作为 hash,这里暂时使用文件名 + 下标,这样后端可以知道当前切片是第几个切片,用于之后的合并切片
随后调用 uploadChunks 上传所有的文件切片,将文件切片,切片 hash,以及文件名放入 formData 中,再调用上一步的 request 函数返回一个 proimise,最后调用** Promise.all **并发上传所有的切片发送合并请求
使用 spark-md5 根据文件内容算出文件 hash
生成 hash
无论是前端还是服务端,都必须要生成文件和切片的 hash,之前我们使用文件名 + 切片下标作为切片 hash,这样做文件名一旦修改就失去了效果,而事实上只要文件内容不变,hash 就不应该变化,所以正确的做法是根据文件内容生成 hash,所以我们修改一下 hash 的生成规则
大文件上传上传几个G的,文件丢失有做处理嘛,有日志吗
大文件上传过程中,文件丢失的情况通常会通过一些机制来处理,以保证上传的文件不会丢失或损坏。下面是一些处理丢失文件的机制和日志记录的建议:
断点续传机制:上传大文件时,可以采用断点续传的方式,即将文件分成多个部分进行上传,每个部分上传完成后,服务器会记录已经上传的位置,以便于下次上传时可以从上次中断的位置继续上传,从而减小上传失败的概率。
文件校验机制:上传完整个文件后,可以对文件进行校验,验证文件的完整性和正确性,以确保文件没有丢失或损坏。一种常用的文件校验方式是使用MD5或SHA256等哈希算法计算文件的散列值,服务器可以比对客户端上传的散列值和服务器端计算的散列值是否相同来判断文件是否丢失或损坏。
日志记录:服务器应该记录每次上传的日志,包括上传时间、上传的文件名称、上传的文件大小、上传成功或失败的状态等信息。这样,在发生文件丢失或其他问题时,管理员可以查看日志文件,找出问题的原因,并采取相应的措施。
总之,对于大文件上传,需要采用多种机制来保证上传的文件不会丢失或损坏,并建议记录上传日志,以便于快速定位和解决问题。
文章列表的长列表优化,使用虚拟滚动 滚动用的是节流做的(这一块用监听滚动条做的,还有什么别的方法嘛)
虚拟滚动是处理长列表的常用技术,其原理是只渲染可见部分,当滚动时动态渲染视口内的列表项,从而减少页面渲染所需的时间和内存占用。虚拟滚动的实现方法可以基于监听滚动条,也可以使用其他方式,下面介绍几种常见的实现方式:
IntersectionObserver 解决方案
通过 IntersectionObserver 的特性,当目标对象中的 entry.isIntersecting 为 true 或者 intersectionRatio > 0 (元素与祖先元素交叉、可见)时,说明本来不可见的元素浮现在视图中,表示它向上或向下滑动,我们动态设置视图中的顶部和底部 id 即可对其判断。当下滑时 entry.traget.id === ‘bottom’,我们修改 start 和 end;同理,当上滑时entry.traget.id === ‘top 时,我们也一样修改 start 和 end
Intersection Observer:Intersection Observer API是浏览器提供的一种观察元素与其祖先元素或视窗交叉情况的机制。使用Intersection Observer可以判断列表项是否在视口内,从而触发渲染和回收,相较于监听滚动条,它更加高效和灵活。
Resize Observer:Resize Observer API是浏览器提供的一种观察元素尺寸变化的机制,用于动态计算可视区域内需要渲染的列表项数量,从而实现虚拟滚动的动态调整。
使用CSS样式实现虚拟滚动:在CSS中设置滚动容器的高度和overflow属性为auto,列表项的高度为固定值,通过控制容器中的子元素数量,从而实现虚拟滚动的效果。
总之,虚拟滚动是处理长列表的有效技术,除了监听滚动条外,还可以使用Intersection Observer、Resize Observer等API或CSS样式实现虚拟滚动,根据实际需求选择最合适的实现方式。
渲染十万条数据有三种解决方案,为虚拟列表、懒加载、时间分片。最优选是虚拟列表,DOM 树上只挂载有限的DOM;懒加载和时间分片的缺点在于插入大量的DOM,占内存运行时会造成卡顿
无论是虚拟列表还是懒加载,传统的做法是 scroll + 节流,这种做法的优势是老 API,兼容性刚刚的,缺点是,滑多了还是会引起性能问题,当然 IntersectionObserver 也是一样的,无非是换了个 API 做“元素是否出现在视图”判断,最好的方案是用 IntersectionObserver(交叉观察器),异步加载、性能消耗小
设计整套权限控制方案
登录权限怎么处理 (动态路由)Vue实现动态路由(和面试官吹项目亮点)
登录逻辑
每个系统都有自己的登录登出逻辑,而我们前端所要做的其实是请求后台,拿到登录权限,带上登录权限,获取用户信息和菜单信息。 在vue项目开发当中,我们一般都是在全局路由钩子做这一系列判断。
菜单权限
通过带有 token 请求头的请求方法,后端可以判断到是哪一个用户,前端也可以通过获取权限接口获得该用户的权限列表,根据权限列表做一份路由映射表,如果后端返回的数据结构与前端的路由设置的数据结构不同,此时还需编写此映射路由的业务功能函数。
如果该用户拥有此路由权限,则通过在全局路由监控中 router.beforeEach 进行 router 中的 addRoutes 方法将有权限的路由配置添加到路由当中,侧边栏也可根据路由列表中的 meta 字段中关键字的判断进行相应的渲染。如果权限的颗粒度小到一个按钮,则可根据后端返回的权限列表映射出的权限参数,通过v-if 进行判断该功能组件是否渲染。在路由管理中通过 router.beforeEach 钩子中判断当前的路由权限是否为空,是的话则可执行获取权限路由的接口:
以前的菜单路由是直接写死在前端,但是当我们直接访问这个路由时,用户还是可以进入到这个功能页面;后来直接改成动态添加路由的方式router.addRoutes。
一个是操作权限,一个是路由访问权限(这里指前端路由)
1.后端返回一个json格式的路由表
2.因为后端传回来的是都是字符串格式的,但前端这里需要的是一个组件对象,写个方法遍历一下,将字符串转换为组件对象
3.利用vue-router的beforeEach、addRoutes、vuex来配合上边两步实现效果
4.左侧菜单拦截根据拿到转换好的路由列表进行展示拦截路由 -> 后端取到路由 -> 保存路由到vuex(用户登录进来只会从后端取一次,其余都从本地取,所以用户,只有退出在登录路由才会更新)
前端有一份动态路由表,等到用户登录拿到用户的角色之后根据当前登录用户的角色去筛选出可以访问的路由,形成一份定制路由表,然后动态挂载路由。,这样做的好处就是,前端每开发一个页面不需要让后端再去配一下路由和权限了,从而避免被后端支配。
然而,路由表又是跟角色挂钩。考虑一种情况,项目上线之后,管理员添加了一个新角色,并且要给这个角色分配菜单。
如果采用将路由表放在前端的话那么每个路由的可访问角色都是写死的,要给新添加的角色分配菜单,只能改前端代码,显然不是很合适。
所以我才用了后者,就是把路由信息放在后端,后端将路由信息和角色关联起来,用户登录之后请求对应的接口拿到属于这个用户的路由信息(也就是菜单),
然后前端对返回的数据格式化,转换成符合vue-router的路由格式,然后动态挂载。将路由信息放在后端,这样就可以对路由进行配置了,比如说超级管理员今天很不高兴,不想让某个角色下的用户访问某个路由,直接在该路由下剔除这个角色就可以了
父子组件通信有哪些
props/$emit
父子组件通信父->子props,
子->父 $on、$emit 获取父子组件实例
获取实例的方式调用组件的属性或者方法parent、children Ref
父->子孙 Provide、inject 官方不推荐使用,但是写组件库时很常用
$emit/$on 自定义事件 兄弟组件通信Event Bus 实现跨组件通信 Vue.prototype.$bus = new Vue() 自定义事件
(event-bus原理:就是一个发布订阅着模式) (注册后挂载到Vue实例,实现监听和触发)
vuex 跨级组件通信Vuex、$attrs、$listeners Provide、inject
$event.bus 发布订阅模式了解嘛
观察者模式和发布订阅模式有什么不同?
发布订阅模式其实属于广义上的观察者模式
在观察者模式中,观察者需要直接订阅目标事件。在目标发出内容改变的事件后,直接接收事件并作出响应。
而在发布订阅模式中,发布者和订阅者之间多了一个调度中心。调度中心一方面从发布者接收事件,另一方面向订阅者发布事件,订阅者需要在调度中心中订阅事件。通过调度中心实现了发布者和订阅者关系的解耦。使用发布订阅者模式更利于我们代码的可维护性。
发布-订阅模式(Publish-Subscribe pattern)是一种常见的软件设计模式,用于实现应用程序内部的解耦和消息传递。该模式的基本思想是将发布者(Publisher)和订阅者(Subscriber)解耦,从而使它们不需要直接相互通信,而是通过一个称为“消息代理”或“事件总线”的中介来传递消息。
在这种模式下,发布者负责产生消息并将其发送到消息代理中心,而订阅者则负责从代理中心接收它们感兴趣的消息。发布者和订阅者都不需要知道对方的存在,因为它们只需要与代理中心进行交互即可。
这种模式的好处是它可以大大降低应用程序的复杂性和耦合度,从而提高其可维护性和可扩展性。此外,它还可以方便地实现异步消息传递和多个订阅者的支持。
在实现中,发布-订阅模式可以通过事件驱动编程(Event-driven programming)来实现。许多编程语言和框架都提供了内置的实现,例如JavaScript中的Node.js框架的事件(Event)和Java中的Java Message Service(JMS)等。
event-bus原理:就是一个发布订阅着模式
是的,事件总线是一个基于发布-订阅模式的消息传递系统,用于在应用程序内或跨应用程序之间传递事件和消息。
在事件总线中,有一个中央的事件总线对象,负责协调和处理消息的传递。发布者(也称为生产者)向事件总线发送事件或消息,而订阅者(也称为消费者)通过向事件总线注册来接收这些事件或消息。
当发布者发送事件时,事件总线会将其传递给所有订阅者。订阅者可以选择仅接收特定类型的事件或消息,也可以选择在特定条件下接收事件。这样,事件总线可以实现高度灵活的消息传递,支持异步消息处理,解耦应用程序组件,并提高应用程序的可扩展性和可维护性。
在实现事件总线时,通常会使用一些特定的框架或库,如Apache Kafka、RabbitMQ、Redis、Google Cloud Pub/Sub等,这些框架提供了各种功能和特性,以满足不同应用场景的需求。
Vue中的key到底有什么⽤?
vue 中 key 值的作用可以分为两种情况来考虑。
第一种情况是 v-if 中使用 key
由于Vue 会尽可能高效地渲染元素,通常会复用已有元素而不是从头开始渲染。因此当我们使用 v-if 来实现元素切换的时候,如果切换前后含有相同类型的元素,那么这个元素就会被复用。如果是相同的 input 元素,那么切换前后用户的输入不会被清除掉,这样是不符合需求的。因此我们可以通过使用 key 来唯一的标识一个元素,这个情况下,使用 key 的元素不会被复用。这个时候 key 的作用是用来标识一个独立的元素。
第二种情况是 v-for 中使用 key
用v-for 更新已渲染过的元素列表时,它默认使用“就地复用”的策略。如果数据项的顺序发生了改变,Vue 不会移动 DOM 元素来匹配数据项的顺序,而是简单复用此处的每个元素。因此通过为每个列表项提供一个 key 值,来以便 Vue 跟踪元素的身份,从而高效的实现复用。这个时候 key 的作用是为了高效的更新渲染虚拟 DOM。
为了给 Vue 一个提示,以便它能跟踪每个节点的身份,从而重用和重新排序现有元素,你需要为每项提供一个唯一 key 属性。理想的 key 值是每项都有唯一 id。
Vue-为什么不建议用数组的下标index作为key
key 是给每一个 vnode 的唯一id,可以依靠 key,更准确,更快的拿到 oldVnode 中对应的 vnode 节点,高效的更新虚拟DOM
用组件唯一的 id(一般由后端返回)作为它的 key,实在没有的情况下,可以在获取到列表的时候通过某种规则为它们创建一个 key,并保证这个 key 在组件整个生命周期中都保持稳定。
如果你的列表顺序会改变,别用 index 作为 key,和没写基本上没区别,因为不管你数组的顺序怎么颠倒,index 都是 0, 1, 2 这样排列,导致 Vue 会复用错误的旧子节点,做很多额外的工作。列表顺序不变也尽量别用,可能会误导新人。
react的Hooks讲几个
当使用 React Hooks 时,可以使用以下一些最常用的 Hooks:
useState
useState 是一个函数,用于在函数式组件中添加状态。它接收一个初始状态值,并返回一个数组,其中第一个元素是当前状态的值,第二个元素是更新该状态的函数。例如,以下代码演示如何使用 useState 来跟踪一个计数器的状态:
1 | |
useEffect
useEffect 用于在组件渲染后执行副作用操作,例如发起网络请求或订阅事件。它接收一个函数和一个可选的依赖数组。在每次渲染后,React 都会检查依赖项数组中的每个元素是否与上一次渲染时的值相同。如果不同,useEffect 将重新运行函数。如果省略依赖项数组,则 useEffect 将在每次渲染后运行函数。以下是一个示例:
1 | |
useContext
useContext 用于在 React 组件之间共享数据,而无需通过层层传递 props。它接收一个上下文对象(由 React.createContext 创建)并返回当前上下文值。例如,以下代码演示了如何使用 useContext 来共享主题值:
1 | |
这里的 ThemeContext 是通过 React.createContext 创建的上下文对象,其值被 MyComponent 组件及其子组件所共享。
Promise讲讲 promise.all race
promise 原理 (回调函数+状态处理队列)
promise 的本质是回调函数,then 方法的本质是依赖收集,它把 fulfilled 状态要执行的回调函数放在一个队列, rejected 状态要执行的回调函数放在另一个队列。待 promise 从 pending 变为 fulfilled/rejected 状态后,把相应队列的所有函数,执行一遍。
.catch能捕捉到.then的错误吗
mounted中.catch报错了是白屏还是这一块组件没用?
是白屏
如果在 JavaScript 中使用了 .catch() 方法捕获异常,但没有对异常进行处理,可能会导致页面出现白屏或其他错误。这通常是因为未处理的异常会中断 JavaScript 的执行,并导致页面的其他部分无法正常工作。
在实际应用中,建议始终对异常进行适当的处理,以确保代码的稳定性和可靠性。可以在 .catch() 方法中添加错误处理逻辑,如向用户显示错误信息、记录错误日志、尝试恢复应用程序状态等等。
除了 .catch() 方法,还可以使用 try…catch 语句来捕获异常,并在 catch 语句块中处理异常。无论使用哪种方式,都应该确保捕获和处理所有可能的异常,以避免页面白屏或其他错误。
扁平化数组js 手撕代码
以下是 JavaScript 中实现扁平化数组的几种方法:
方法一:使用递归
1 | |
方法二:使用 reduce 方法
1 | |
方法三:使用扩展运算符
1 | |
方法四:使用迭代器
1 | |
以上是一些常见的扁平化数组的方法。无论使用哪种方法,都需要确保对于所有可能的数组嵌套层次,都可以正确地扁平化数组。
反问
- 技术栈 react
- 公司项目 主要做toB的sass平台 一些文件的上传,素材的处理,(公司目前前端3个左右 后端有几个,预计招聘20个开发)
- 反问能给一些建议
答: 建议多做项目,公司的项目,把事情做的最好,不只是完成。(完成之后看看有没有别的更好的方法解决)
面试总结(二面)000
自我介绍
vue和react的区别 (从原理上解释)
从原理上来说,Vue和React的区别主要体现在以下几个方面:
数据绑定方式:Vue采用双向数据绑定,React采用单向数据流。在Vue中,每个组件都有一个响应式的数据对象,当数据发生变化时,视图会自动更新。而在React中,数据是通过props从父组件向子组件传递的,子组件需要通过回调函数向父组件传递数据。
组件化开发方式:Vue中的组件化开发更加直观和简单,每个组件都包含了模板、逻辑和样式,可以直接编写。而在React中,组件的逻辑和样式是通过JavaScript代码编写的,需要使用JSX语法进行组件开发。
数据流管理方式:Vue中提供了Vuex状态管理库,可以更好地管理大型应用中的状态,包括状态的修改和响应。而React则更倾向于使用第三方状态管理库,例如Redux。
渲染性能优化:Vue和React都采用了虚拟DOM技术,但是它们的渲染性能优化方式有所不同。在Vue中,通过模板编译和静态分析等技术,可以减少虚拟DOM的比较和计算;而在React中,通过Fiber架构和异步渲染等技术,可以更好地控制渲染的流程和响应性能。
总体而言,Vue和React的区别主要在于数据绑定方式、组件化开发方式、数据流管理方式和渲染性能优化方式等方面。在实际开发中,我们可以根据具体的应用场景和需求选择合适的框架,以提高开发效率和应用程序性能。
为什么vue采用的是双向数据绑定,react用的是单向数据流
Vue和React是两个流行的前端框架,它们的数据绑定方式不同,其中Vue采用的是双向数据绑定,React采用的是单向数据流。
双向数据绑定指的是数据的变化会立即反映到视图上,同时用户的交互操作也会立即更新数据。在Vue中,使用v-model指令可以实现双向数据绑定。双向数据绑定的优点是可以减少开发人员的代码量和重复性工作,同时也方便用户操作和体验。
而单向数据流指的是数据只能从父组件传递到子组件,子组件无法直接修改父组件的数据。在React中,父组件可以通过props将数据传递给子组件,子组件可以通过回调函数将修改后的数据传递给父组件。单向数据流的优点是可以更好地控制数据流向,避免出现意料之外的数据变化,同时也方便进行数据的追踪和调试。
选择双向数据绑定还是单向数据流,主要取决于具体的应用场景和开发需求。Vue适用于开发中小型应用,双向数据绑定可以提高开发效率;React适用于开发大型应用,单向数据流可以提高代码的可维护性和可读性。
typeScript有了解嘛
原型链的顶端是什么(如果找不到是什么)
在JavaScript中,每个对象都有一个原型(prototype)属性,指向它的原型对象。原型对象也有原型属性,指向它的原型对象,这样就形成了原型链。
原型链的顶端是Object.prototype,它是所有对象的祖先对象。Object.prototype的原型指向null,即它没有原型对象,所以当在原型链中找不到某个属性或方法时,就会返回undefined,而不是继续查找。
例如,当我们创建一个对象,并尝试访问它的属性或方法时,JavaScript引擎会先查找该对象本身是否具有该属性或方法,如果没有,则沿着原型链向上查找,直到找到该属性或方法或者到达Object.prototype为止。如果在整个原型链上都没有找到该属性或方法,那么就返回undefined。
总之,原型链的顶端是Object.prototype,它是所有对象的祖先对象,当在原型链中找不到某个属性或方法时,就会返回undefined。(这个答错了,回答的是null)
事件循环(如果微任务里面产生了微任务是继续执行微任务还是下一个宏任务?) —是执行完产生的所有微任务再执行下一个宏任务
在JavaScript中,事件循环机制(Event Loop)用于协调处理事件和执行代码的顺序。它不断地从任务队列中取出任务,执行任务,并在任务执行完毕后等待新的任务加入队列。
在事件循环中,每次执行一个宏任务(例如脚本的整体代码、setTimeout/setInterval回调函数等),都会在宏任务执行完毕后先执行所有的微任务(例如Promise回调函数、MutationObserver回调函数等),然后才会执行下一个宏任务。这个过程称为“微任务队列优先于宏任务队列”。
如果在微任务队列中产生了新的微任务,那么它会被添加到微任务队列的末尾,等待下一次事件循环时执行。如果在微任务执行过程中产生了新的微任务,那么这些新的微任务也会被依次添加到微任务队列的末尾。
举个例子,假设有如下代码:
1 | |
当上述代码执行时,它会依次执行如下步骤:
执行第一个宏任务(即整体代码)。
执行第一个微任务,即输出“微任务1”。
在执行微任务的过程中,产生了新的微任务“微任务2”,它会被添加到微任务队列的末尾。
第一个微任务执行完毕后,开始执行第二个微任务,即输出“微任务2”。
执行第二个宏任务,即输出“宏任务1”。
在执行第二个宏任务的过程中,产生了新的微任务“微任务3”,它会被添加到微任务队列的末尾。
第二个宏任务执行完毕后,开始执行微任务队列中的剩余任务,即输出“微任务3”。
综上所述,如果微任务队列中产生了新的微任务,它们会被依次添加到微任务队列的末尾,等待下一次事件循环时执行,不会影响当前的微任务执行。网络模型 (5层-7层)http在哪一层–应用层
5层–(应-运-网-链-物) –(应用层-运输层-网络层-链路层-物理层)
7层–(应-(表现层-会话层)运-网-链-物)缓存有哪些(强缓存/协商缓存)
浏览器与服务器通信的方式为应答模式,即是:浏览器发起HTTP请求 – 服务器响应该请求。那么浏览器第一次向服务器发起该请求后拿到请求结果,会根据响应报文中HTTP头的缓存标识,决定是否缓存结果,是则将请求结果和缓存标识存入浏览器缓存中
浏览器每次发起请求,都会先在浏览器缓存中查找该请求的结果以及缓存标识
浏览器每次拿到返回的请求结果都会将该结果和缓存标识存入浏览器缓存中
以上两点结论就是浏览器缓存机制的关键,他确保了每个请求的缓存存入与读取,只要我们再理解浏览器缓存的使用规则,那么所有的问题就迎刃而解了。为了方便理解,这里根据是否需要向服务器重新发起HTTP请求将缓存过程分为两个部分,分别是强制缓存和协商缓存。
强制缓存强制缓存就是向浏览器缓存查找该请求结果,并根据该结果的缓存规则来决定是否使用该缓存结果的过程
当浏览器向服务器发起请求时,服务器会将缓存规则放入HTTP响应报文的HTTP头中和请求结果一起返回给浏览器,控制强制缓存的字段分别是 Expires 和 Cache-Control,其中Cache-Control优先级比Expires高。强制缓存的情况主要有三种(暂不分析协商缓存过程),如下: 状态仍然返回200,但不会请求数据,在浏览器中能明显看到from cache字样。
- 不存在该缓存结果和缓存标识,强制缓存失效,则直接向服务器发起请求(跟第一次发起请求一致)。
- 存在该缓存结果和缓存标识,但该结果已失效,强制缓存失效,则使用协商缓存。
- 存在该缓存结果和缓存标识,且该结果尚未失效,强制缓存生效,直接返回该结果
协商缓存协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程
Etag >Last-Modifie Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304
同样,协商缓存的标识也是在响应报文的HTTP头中和请求结果一起返回给浏览器的,控制协商缓存的字段分别有:Last-Modified / If-Modified-Since 和 Etag / If-None-Match,其中Etag / If-None-Match的优先级比Last-Modified / If-Modified-Since高。协商缓存主要有以下两种情况:
- 协商缓存生效,返回304
- 协商缓存失效,返回200和请求结果结果
传送门 ☞ #彻底理解浏览器的缓存机制
博客地址http的content-type有哪些
HTTP的Content-Type请求头字段用于指定发送给客户端的实体的类型。常见的Content-Type值及其含义如下:除了上述列出的类型之外,还有很多其他的Content-Type类型,这些类型可以根据实际需要进行自定义。Content-Type值通常与HTTP请求的Accept头字段一起使用,以便指定客户端所期望的响应类型。例如,如果客户端希望接收JSON格式的响应,它可以将Accept头字段设置为“application/json”。1
2
3
4
5
6
7
8
9
10
11text/plain:纯文本格式,没有指定格式的字节流。
text/html:HTML格式的文本。
text/css:Cascading Style Sheets (CSS) 样式表。
text/javascript:JavaScript脚本代码。
application/json:JSON格式的数据。
application/xml:XML格式的数据。
application/pdf:PDF文档格式。
image/jpeg:JPEG格式的图片。
image/png:PNG格式的图片。
audio/mpeg:MPEG音频文件。
video/mp4:MP4格式的视频文件。
如何设置呢
在HTTP请求中设置Content-Type请求头字段通常有两种方法:
通过手动设置请求头字段:
在大多数HTTP客户端中,您可以手动设置Content-Type请求头字段。例如,使用axios库发送HTTP请求时,您可以通过设置headers选项来指定Content-Type值,例如:
1 | |
这将向服务器发送一个Content-Type值为“application/json”的请求。
使用特定的API方法:
在某些HTTP客户端库中,例如jQuery和Fetch API,您可以使用特定的API方法来发送不同类型的请求,这些方法将自动设置Content-Type请求头字段。例如,使用Fetch API发送JSON格式的请求时,您可以使用以下代码:
1 | |
这将自动设置Content-Type请求头字段为“application/json”。
请注意,Content-Type请求头字段必须与请求实体的格式匹配,否则服务器可能无法正确解析请求。因此,在设置Content-Type值时,请确保选择正确的格式。
后端怎么修改返回的status.code(状态码)
HTTP状态码是由服务器返回的标准HTTP响应的一部分,它们指示请求的成功或失败状态。状态码是HTTP协议的一部分,它们定义了不同类型的响应,例如200表示成功,404表示未找到,500表示服务器错误等等。
由于HTTP状态码是由服务器返回的,客户端无法直接修改它们。只有服务器可以控制响应的状态码,根据服务器处理请求的结果来生成适当的状态码。如果您想修改HTTP状态码,您需要访问服务器并修改响应的代码。
在Node.js中,您可以使用内置的HTTP模块来创建HTTP服务器,并在响应对象上设置HTTP状态码。以下是一个简单的示例:
1 | |
在这个示例中,我们创建了一个HTTP服务器,并在响应对象上设置了状态码为404。在实际应用中,您可以根据请求的处理结果动态设置状态码。
除了设置状态码外,您还可以设置其他HTTP响应头,例如内容类型、缓存控制、跨域等。例如,您可以使用以下代码设置响应的内容类型:
1 | |
在这个示例中,我们将响应的内容类型设置为HTML。
总之,在Node.js中,您可以通过设置响应对象的状态码和其他HTTP响应头来控制HTTP响应。
除了示例中设置404状态码以外,您可以通过将res.statusCode属性设置为任何有效的HTTP状态码来设置响应的状态码。例如,以下是一些常见的HTTP状态码及其含义:
1 | |
res.statusCode = 500;
然后,您可以使用res.end()方法向客户端发送响应内容。例如:
res.end(‘Server Error’);
在实际应用中,您需要根据请求的处理结果设置适当的状态码,以便客户端可以正确处理响应并采取适当的行动。
跨域怎么实现?jsonp的原理是什么?
跨域,指的是浏览器不能执行其他网站的脚本。浏览器执行javascript脚本时,会检查这个脚本属于哪个页面,如果不是同源页面,就不会被执行
解决办法:
- JSONP:注意JSONP只支持GET请求,不支持POST请求。
原理:ajax请求受同源策略影响,不允许进行跨域请求,而script标签src属性中的链接却可以访问跨域的js脚本,利用这个特性,服务端不再返回JSON格式的数据,而是返回一段调用某个函数的js代码,在src中进行了调用,这样实现了跨域。 — callback - 代理:写后端接口,在后端调用页面拿到返回值返回给html文件。相当于绕过了浏览器,就不会存在跨域问题。例;(nigx反向代理)
- CORS CORS(Cross-origin resource sharing)跨域资源共享 服务器设置对CORS的支持原理:服务器设置Access-Control-Allow-Origin HTTP响应头之后,浏览器将会允许跨域请求
1
2header('Access-Control-Allow-Origin:*');//允许所有来源访问
header('Access-Control-Allow-Method:POST,GET');//允许访问的方式 - proxy代理 目前常用方式,通过服务器设置代理 在 vue.config.js 项目中配置 proxy 解决跨域问题
- window.postMessage() 利用h5新特性window.postMessage()
Options(CORS跨域,非简单请求)
1.HTTP的options方法作用
检测服务器所支持的请求方法。(比如:‘/user’路由支持哪些方法:get、post、delete…)
CORS中的预检请求(检测某个接口是否支持跨域)
2.allowedMethods方法
响应options方法,告诉它所支持的请求方法
相应的返回405(不允许)和501(没实现)(比如我使用delete,会返回405,因为我没有写这个接口。但我使用link接口请求,会返回501,因为koa里不支持link请求)
options 请求就是预检请求,可用于检测服务器允许的 http 方法。当发起跨域请求时,由于安全原因,触发一定条件时浏览器会在正式请求之前自动先发起 OPTIONS 请求,即 CORS 预检请求,服务器若接受该跨域请求,浏览器才继续发起正式请求。
uniapp为什么可以跨端
UniApp是一种基于Vue.js框架的跨平台开发解决方案,它可以使用一套代码同时构建多个不同平台的应用程序,包括iOS、Android、H5和微信小程序等。UniApp之所以可以实现跨端,主要有以下几个原因:
采用基于Web标准的技术:UniApp采用了基于Web标准的技术,包括HTML、CSS和JavaScript等,这些技术可以在各个平台上得到很好的支持。因此,UniApp能够实现跨端。
基于多端适配的框架:UniApp框架对多端适配进行了优化,它会根据不同的平台,生成对应的代码和样式,从而能够适配多个不同的平台。
借助原生能力实现跨端:UniApp还可以借助原生能力实现跨端。例如,UniApp可以调用原生的API来实现一些特定功能,从而使得应用程序在各个平台上都能够具有相同的特性和体验。
综上所述,UniApp之所以可以实现跨端,是因为它采用了基于Web标准的技术,并且通过框架的多端适配以及借助原生能力的方式,来实现跨平台的开发。
了解浏览器原理 –说成http请求url了
浏览器是一种用于访问互联网的软件应用程序,它通过解析 HTML、CSS、JavaScript 等网络资源,将它们呈现给用户。以下是浏览器的一些基本原理:
用户界面:浏览器的用户界面包括地址栏、后退和前进按钮、书签等等。浏览器的用户界面通常由浏览器的开发者设计,用户可以根据自己的喜好进行个性化设置。
渲染引擎:渲染引擎负责将网页内容解析成可视化的格式。主要的渲染引擎有 Blink(Chrome 和 Opera 使用)、Gecko(Firefox 使用)以及 WebKit(Safari 使用)。渲染引擎可以理解 HTML、CSS、JavaScript 等网页资源,并将它们渲染成用户可以看到的样式。
JavaScript 解释器:JavaScript 解释器负责解析和执行 JavaScript 代码。现代浏览器通常使用 Just-in-Time(JIT)编译器,以便提高 JavaScript 的性能和效率。
布局引擎:布局引擎负责处理网页的布局和排版。它会根据渲染引擎生成的网页内容,将内容排版成适合于显示的格式,并在用户界面中进行展示。
网络:浏览器的网络组件负责从网络中获取所需的资源,如 HTML 文件、CSS 样式表、JavaScript 脚本等等。它通过使用 HTTP 或 HTTPS 协议,向服务器请求资源并获取响应,然后将响应的内容提供给渲染引擎进行解析和渲染。
数据存储:浏览器还提供了一些数据存储的机制,用于存储本地数据,如 cookie、localStorage 和 sessionStorage 等等。这些存储机制使得网站可以保存用户的偏好设置、登录状态等等,并提供一种用于在浏览器和服务器之间传输数据的机制。
性能优化有了解吗 –能讲讲吗
http2>http1(优势?)
后面讲了一下项目中的防抖节流
如何减少项目中的bug
需求澄清,串讲,反串讲,设计,编码,代码检视,用例评审,自测。
减少项目中的bug需要采取一系列措施,下面是一些可能有用的建议:
1.编写高质量的代码:编写高质量的代码是减少bug的最有效方法之一。为了使代码更加清晰、简洁、可读性更好,可以通过代码规范、注释、文档以及自动化测试等方式来实现。
2.使用自动化测试:自动化测试可以提高代码质量,减少bug的出现。可以采用单元测试、集成测试、接口测试、性能测试等方式来确保代码可靠性。
3.代码审查:定期进行代码审查,及时发现并修复潜在的问题,这有助于提高代码质量。
4.使用版本控制工具:使用版本控制工具可以追踪代码变更,并允许你回退到之前的版本。这可以防止错误代码被部署到生产环境,并使团队成员更容易协作。
5.使用可靠的第三方库:对于需要使用第三方库的项目,选择一个可靠的、有良好口碑的库,可以减少出现bug的机会。同时,需要及时更新第三方库,以避免遗留的安全漏洞和错误。
总之,为了减少项目中的bug,需要具备高质量的代码、自动化测试和代码审查等技能来检查、分发并减少代码错误。
配置一套符合团队习惯且规范的husky能讲讲吗
反问? 公司的业务和项目 –公司的培养计划和晋升计划?
建议 (不只是要会用,原理这一块得熟悉)
二
面试总结
图谱可视化分析项目 是干啥的(详细讲讲是有啥作用,分析了啥,数据挖掘了什么)
应用知识图谱技术和图分析算法进行知识挖掘、知识分析的工具。与统计分析相比,GKP图谱可视分析在社群发现、最短路径分析、关键节点/因素洞察、活跃因素分析、异常发现等领域更加直观和高效。
[司法-知识卡片]检索卡片功能实现
卡片类型 —卡片类型包含案由卡片、案件卡片、内部文书卡片、裁判文书卡片、典型案例卡片、法律法规卡片、法律条文卡片、当事人卡片、法院卡片、法官卡片、律师事务所卡片、律师卡片等。根据命中的实体显示卡片内容,无命中实体时,只显示检索结果,不显示卡片信息。
案件卡片 —-案件卡片主要显示案件的字段信息,包含案件的名称、案由、适用程序、法院名称、承办部门、承办人、简要案情等。可直接链接进入案件详情页进行查看。
裁判文书卡片 —-显示裁判文书的名称、法院、案号、案由、案件类型、文书类型、裁判日期、判决结果(原告胜诉) 、案件要素等,:并切换显示事实认定段、裁判理由段、引用法条段、裁判结果段的内容支持跳转到裁判文书详情页进行查看。
[司法-实体对比)]对比功能实现
加入对比— 列表加入对比 律师、当事人的列表页可加入对比栏
详情页加入对比 律师、当事人、法院、法官、律师事务所等的详情页可加入对比栏
卡片加入对比 律师、当事人、法院、法官、律师事务所检索结果的卡片显示中,可加入对比栏
对比栏 — 去对比 点击去对比,进入对比详情页
取消对比项 点击对比栏中某个对比项中的取消按钮,可排除该对比项
同类对比 对比栏中的对比项,必须为同一类,当加入不同类时,之前的对比项自动取消,只保留最新加入的对比项。
对比详情 —对比详情 以表格的形式,对比各个对比想的对比维度。
律师画像《图谱版》 – 搜索与筛选—维度检索 支持选择搜索维度进行搜索,可选维度包括律师姓名、所在律所等维度进行检索。
检索结果列表显示 支持显示律所的姓名、所在律所、裁判文书数量等信息
列表分页 支持检索结果列表分页展示
可配置检索功能 升级可配置检索功能
律师信息显示 律师详情页显示律师的基本信息,包括姓名、所在律所、裁判文书数量等
画像详情 律师信息显示 律师详情页显示律师的基本信息,包括姓名、所在律所、裁判文书数量等
可视化画像 画像信息包括作为原告代理人案件胜败诉分析、作为被告代理人胜败诉分析、法院分布案由分布、案件裁判时间分布、案件审理程序分布、法官分布、结案方式分布等。
筛选条件 支持对律师相关的裁判文书按照多维检索条件进行进一步检索,检索结果影响画像统计以及数据列表的显示筛选条件默认收起,可手动展开
当事人画像(图谱版) 搜索与筛选 维度检索 支持选择搜索维度进行搜索,可选维度包括当事人名称等维度进行检索。
检索结果列表显示 支持显示当事人的姓名/名称、住所地、裁判文书数量等信息
列表分页 支持检索结果列表分页展示
可配置检索功能 升级可配置检索功能
画像详情 当事人信息显示 当事人详情页显示律师的基本信息,包括姓名/名称、住所地数量等
可视化画像 画像信息包括作为原告案件胜败诉分析、作为被告胜败诉分析、法院分布、案由分布案件裁判时间分布、案件审理程序分布、法官分布、结案方式分布等。
筛选条件 支持对当事人相关的裁判文书按照多维检索条件进行进一步检索 检索结果影响画像统计以及数据列表的显示。筛选条件默认收起可手动展开
后端返回的数据类型是什么?
后端返回的数据类型可以是多种形式,最常见的包括:
JSON(JavaScript Object Notation):JSON是一种轻量级的数据交换格式,它基于JavaScript语法,易于读写和解析。许多Web应用程序使用JSON作为数据传输格式,使得前端可以方便地处理和展示后端返回的数据。
XML(Extensible Markup Language):XML是一种标记语言,可用于描述和传输数据。与JSON相比,XML通常更为复杂,但也具有广泛的支持和应用场景。
HTML(Hypertext Markup Language):HTML是一种用于开发Web页面的标记语言。虽然HTML主要用于前端显示,但在某些场景下,后端也可以将数据以HTML格式返回给客户端。
Text:后端有时也可能将数据以纯文本形式返回,这种情况下需要前端自行解析和处理数据。
二进制数据:有些情况下,后端可能会返回二进制数据,如图像、视频、音频等。此时,前端需要根据数据类型进行解析和处理。
需要注意的是,不同的后端接口可能采用不同的数据格式,因此前端需要根据实际情况进行处理。同时,后端返回的数据还需要考虑数据安全性和可靠性等问题。
后端返回的数据结构可能有多种形式,以下是一些常见的数据结构:
数组(Array):数组是一组有序的数据集合,每个元素可以是任何类型的数据。在很多场景下,后端会将一组数据封装为一个数组,并将其返回给前端。
对象(Object):对象是一组键值对的集合,其中每个键对应一个值。后端通常会将一些相关联的数据封装在一个对象中,并将其作为响应数据返回给前端。
树形结构(Tree):树形结构是一种层级化的数据结构,它由根节点、子节点等组成,并且节点之间具有父子关系。在某些情况下,后端会将返回的数据组织成树形结构,以帮助前端更好地处理和展示数据。
图形结构(Graph):图形结构是由节点和边组成的数据结构,它可以用于表示复杂的关系和网络。在某些场景下,后端可能会将返回的数据组织成图形结构,以便前端进行处理和分析。
集合(Set):集合是一组互不相同的元素的集合。在某些场景下,后端也可能会将数据封装为一个集合,并将其返回给前端。
键值对(Key-Value):键值对是一种简单的数据结构,它由一个键和一个与之对应的值组成。后端通常会使用键值对来描述一些配置信息或元数据等。
需要注意的是,以上数据结构并不是一成不变的,实际上,后端会根据不同的业务需求和开发场景,采用不同的数据结构来组织和返回数据。前端需要根据实际情况进行选择和解析,以便更好地利用后端返回的数据。
后端返回的数组结构和树形结构js代码示例
1 | |
大文件上传,使用切片上传形式,支持上传、暂停、续传
虚拟dom–Virtual DOM讲讲–还有应用场景
闭包是应用场景–项目中的–防抖
私下的学习习惯
再讲讲你项目中的难点–(我讲了这个–实现select下拉搜索,无限滚动)
反问
建议–多了解业务(前端更贴近用户)
技术栈Vue
1. 负责实体”全息档案”画像配置、实体”全息档案”对比开发、文档分析模块开发
对比
对于多个数组的情况,可以使用 JavaScript 的 reduce 方法结合上一步的判断逻辑来实现。
示例代码如下:
1 | |
在上面的代码中,我们定义了一个名为 compareArrays 的函数,该函数使用了 ES6 的 rest 参数语法来接收任意数量的数组参数。然后,我们使用 reduce 方法将所有数组两两比较,并根据前文所述的判断逻辑返回最终比较结果。
需要注意的是,reduce 方法遍历数组时是从第 2 个元素开始的,因此我们需要在比较之前先判断前后两个数组长度是否相等。此外,如果传入空数组或只有一个数组参数,则该方法会直接返回 undefined,因此需要特殊处理这种情况。
三
面试记录 (面试那边有我这的回声-面试体验不怎么好)(数组和对象的方法不怎么熟悉了,回去看看)
自我介绍
问为什么没有写CSS,这家公司比较注重基础
js数据类型
boolean, number, string,null,undefined,object(6中基本数据类型)
symbol,bigInt(新增的数据类型)
js判断类型
判断方法:typeof(),instanceof,constructor,Object.prototype.toString.call()等
1. typeof 其中数组、对象、null都会被判断为Object,其他判断都正确
返回数据类型,包含这7种: number、boolean、symbol、string、object、undefined、function。typeof null 返回类型错误,返回object ,引用类型,除了function返回function类型外,其他均返回object。其中,null 有属于自己的数据类型 Null
2. instanceof 只能判断引用数据类型,不能判断基本数据类型
1 | |
instanceof 是用来判断 A 是否为 B 的实例,表达式为:A instanceof B,如果 A 是 B 的实例,则返回 true,否则返回 false。 在这里需要特别注意的是:instanceof 检测的是原型,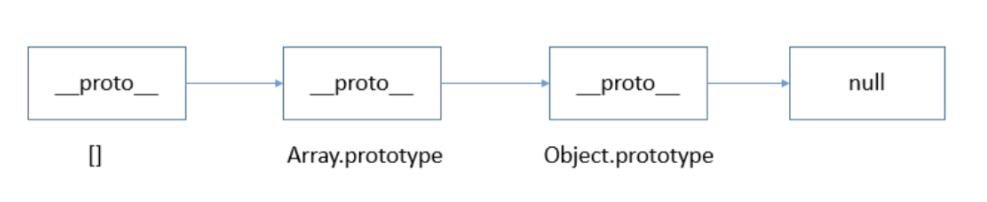
由上图可以看出[]的原型指向Array.prototype,间接指向Object.prototype, 因此 [] instanceof Array 返回true, [] instanceof Object 也返回true。
instanceof 只能用来判断两个对象是否属于实例关系, 而不能判断一个对象实例具体属于哪种类型。
3. constructor(2个作用 一是判断数据的类型,二是对象实例通过constructor对象访问它的构造函数。需要注意的事情是如果创建一个对象来改变它的原型,constructor就不能来判断数据类型了)
1 | |
constructor是原型prototype的一个属性,当函数被定义时候,js引擎会为函数添加原型prototype,并且这个prototype中constructor属性指向函数引用, 因此重写prototype会丢失原来的constructor。
不过这种方法有问题:
1:null 和 undefined 无constructor,这种方法判断不了。
2:还有,如果自定义对象,开发者重写prototype之后,原有的constructor会丢失,因此,为了规范开发,在重写对象原型时一般都需要重新给 constructor 赋值,以保证对象实例的类型不被篡改。
4. toString 这个是最完美的
toString() 是 Object 的原型方法,调用该方法,默认返回当前对象的 [[Class]] 。这是一个内部属性,其格式为 [object Xxx] ,其中 Xxx 就是对象的类型。
对于 Object 对象,直接调用 toString() 就能返回 [object Object] 。而对于其他对象,则需要通过 call / apply 来调用才能返回正确的类型信息。
原理
在toString方法被调用时,会执行下面的操作步骤:
获取this对象的[[Class]]属性的值.
计算出三个字符串”[object “, 第一步的操作结果Result(1), 以及 “]”连接后的新字符串.
返回第二步的操作结果Result(2).
判断类型举例:
1 | |
如何判断一个对象是数组还是对象
一、typeof判断数据类型(判断数组跟对象都返回object)
二、instanceof判断对象的原型链是否是指向构造函数的prototype
1 | |
三、对象的constructor属性
1 | |
四、Object.prototype.toString.call(arr)
利用对象的toString可以准确判断是什么类型,call()改变this指向,这里是借用Object的方法,然后有人可能会问为什么不直接用arr.toString而要借用Object的方法,
1 | |
直接用tostring()
1 | |
因为toString为Object原型上的方法,而Array、Function都是Object的实例,实例重新改写了原型上的toString方法,不同的对象调用toString方法,调用的是改写之后的方法
(转成各种类型的字符串),而不会调用Object原型上的toString()方法,因此直接调用不能判断对象类型
1 | |
我们可以看到,删除实例上的toString方法后调用的是Object原型上的toString()方法,返回对象类型
五、es6的方法——Array.isArray()
1 | |
六、看好多博客说用length判断,这个其实不准确
1 | |
对象可以直接添加length这个属性,就无法区分了
数组常用方法(一般方法)
push(),pop(),shift(),unshift(),splice(),sort(),reverse(),map()等
会改变原始数组的方法有
1 | |
不改变原始数组的方法有
1 | |
forEach map(ES5)的区别
能用forEach()做到的,map()同样可以。反过来也是如此
map()会分配内存空间存储新数组并返回,forEach()不会返回数据。
forEach()允许callback更改原始数组的元素。map()返回新的数组。 map() 不会改变原始数组。
map() forEach() (数据为基本类型,改变其值(不会改变))(数据为引用类型,改变其属性方法的值(会改变))
map() 可以利用 return 语句来返回值,该值将被放入新数组中。forEach() 方法不能使用 return 语句返回值。
map和forEach是按 (value,key)的方式遍历的
1 | |
如何判断一个对象为空
判断一个对象为空,可以使用以下方法:
- 使用
Object.keys()方法判断对象是否有属性
1 | |
该方法将返回一个由对象的所有可枚举属性组成的数组,如果数组长度为0,则表示该对象没有属性,即为空对象。
- 使用
for...in循环判断对象是否有属性
1 | |
- 使用
JSON.stringify()方法判断对象是否为空
1 | |
该方法将对象序列化为JSON字符串,如果该字符串内容为’{}’,则表示该对象为空对象。
需要注意的是,以上三种方法都是判断对象是否完全为空(即没有任何属性),如果对象有原型链上的属性或者仅包含空字符串、null、undefined等值,则不算为空对象。
Array.from()方法
Array.from() 方法是 JavaScript 内置的一个静态方法,用于将类数组对象或可遍历对象(例如 Set 和 Map)转换为真正的数组。
Array.from() 方法有两个参数:第一个参数指定要转换的对象,第二个参数(可选)指定一个映射函数,可以对每个元素进行处理。如果没有提供第二个参数,则相当于只做了一次浅拷贝。
例如,将一个字符串转换为字符数组:
1 | |
使用映射函数将数组中的每个元素都平方:
1 | |
使用 Array.from() 方法可以方便地将一个类数组对象或可遍历对象转换为数组,避免手动写循环或者使用其他方法来实现这个功能。需要注意的是,在转换过程中,原始对象的属性和方法会被忽略,只有索引位置上的值会被保留。
JavaScript 原型,原型链? 有什么特点?
在 js 中我们是使用构造函数来新建一个对象的,每一个构造函数的内部都有一个 prototype 属性值,这个属性值是一个对象,这个对象包含了可以由该构造函数的所有实例共享的属性和方法。
当我们使用构造函数新建一个对象后,在这个对象的内部将包含一个指针,这个指针指向构造函数的 prototype 属性对应的值,在 ES5 中这个指针被称为对象的原型。
一般来说我们是不应该能够获取到这个值的,但是现在浏览器中都实现了__proto__属性来让我们访问这个属性,但是我们最好不要使用这个属性,因为它不是规范中规定的。ES5 中新增了一个Object.getPrototypeOf() 方法,我们可以通过这个方法来获取对象的原型。
当我们访问一个对象的属性时,如果这个对象内部不存在这个属性,那么它就会去它的原型对象里找这个属性,这个原型对象又会有自己的原型,于是就这样一直找下去,也就是原型链的概念。原型链的尽头一般来说都是 Object.prototype所以这就是我们新建的对象为什么能够使用 toString() 等方法的原因。
2、隐式原型也是一个对象,是指向我们构造函数的原型
3、除了最顶层的Object对象没有__proto_,其他所有的对象都有__proto__,这是隐式原型
4、隐式原型__proto__的作用是让对象通过它来一直往上查找属性或方法,直到找到最顶层的Object的__proto__属性,它的值是null,这个查找的过程就是原型链
特点:
JavaScript 对象是通过引用来传递的,我们创建的每个新对象实体中并没有一份属于自己的原型副本。当我们修改原型时,与之相关的对象也会继承这一改变。
面试题–原型链的顶端是什么(如果找不到是什么)
在JavaScript中,每个对象都有一个原型(prototype)属性,指向它的原型对象。原型对象也有原型属性,指向它的原型对象,这样就形成了原型链。
原型链的顶端是Object.prototype,它是所有对象的祖先对象。Object.prototype的原型指向null,即它没有原型对象,所以当在原型链中找不到某个属性或方法时,就会返回undefined,而不是继续查找。
例如,当我们创建一个对象,并尝试访问它的属性或方法时,JavaScript引擎会先查找该对象本身是否具有该属性或方法,如果没有,则沿着原型链向上查找,直到找到该属性或方法或者到达Object.prototype为止。如果在整个原型链上都没有找到该属性或方法,那么就返回undefined。
总之,原型链的顶端是Object.prototype,它是所有对象的祖先对象,当在原型链中找不到某个属性或方法时,就会返回undefined。(这个答错了,回答的是null)
js 获取原型的方法?
p.__proto__
p.constructor.prototype
Object.getPrototypeOf(p)
hasOwnProperty表示是否有自己的属性。这个方法会查找一个对象是否有某个属性,但是不会去查找它的原型链
了解Vue底层原理(简历上写了,讲讲Object.definProperty从原生上讲讲) 除了getter,setter还有?
Object.defineProperty() 是 JavaScript 中一个原生的方法,用于在一个对象上定义新属性或者修改现有属性的特性(例如可写性、可枚举性和可配置性)。
该方法接收三个参数:要定义属性或特性的对象、属性名称或符号、以及一个描述符对象。描述符对象包含如下可选属性:
value:属性的值。writable:是否允许修改属性的值,默认为false。enumerable:属性是否可以被枚举,默认为false。configurable:属性是否可以被删除或者修改特性,默认为false。
例如,使用 Object.defineProperty() 方法定义一个只读属性:
1 | |
在上面的例子中,使用 Object.defineProperty() 方法将一个只读属性 readOnly 添加到了对象 obj 上,并且指定了其属性值为 42,不可写但可枚举。当尝试修改该属性时,会抛出一个类型错误。
Object.defineProperty() 方法可以用于创建一些高度定制化的对象特性,例如实现类似 Vue.js 的数据双向绑定功能。需要注意的是,在使用该方法时,应避免过多地修改对象的特性,以免影响代码的可读性和维护性。
promise有多个.then方法如何中断第二个.then呢 (这里紧张了答成promise.resolved了,是rejected)
在 Promise 中,如果想要中断执行链中的某个 .then() 方法,可以通过抛出一个错误(或返回一个被拒绝的 Promise)来实现。这样做会导致 Promise 执行链跳过后续的 .then() 方法,直接进入 .catch() 或者全局异常处理程序。
具体来说,可以在 .then() 方法中进行条件判断,如果不满足条件,则抛出一个错误。例如:
1 | |
在上面的例子中,如果上一个 .then() 返回的结果是 'some value',则会继续执行下一个 .then();否则,就会抛出一个 Error,中断执行链,直接进入 .catch() 部分处理异常情况。
需要注意的是,由于 Promise 的异步特性,上述中断操作并不能立即生效,而是需要等到执行栈清空后才会被捕获和处理。因此,在使用 Promise 进行条件判断时,应该特别注意错误处理和异常情况的处理,以避免不必要的问题和副作用。
不使用for循环如何生成长度100的数组,数组的值为他的下标
可以使用 Array.from() 方法来生成指定长度的数组,然后结合第二个参数中定义的映射函数将每个元素转换为其下标。
以下是示例代码:
1 | |
这将生成一个长度为 100 的数组,其中每个元素的值都等于它的下标。第一个参数 { length: 100 } 定义了数组的长度为 100,而第二个参数 (item, index) => index 将每个元素转换为其下标。在这里,我们使用了下划线 _ 来占位 item 参数,因为它不需要使用。
讲一下https和http的区别
https加密
入行前端做项目最大的收获是(自我价值/公司价值)
作为一个 AI 而非人类,我没有亲身经历过前端开发的工作和项目经验。不过,根据从程序员们的反馈中综合整理,以下是一些可能会获得的收获:
实践能力:通过实际的项目开发,可以更好地理解并熟悉前端技术栈,提高自己的实践能力。
团队协作:在团队中完成项目需要与其他成员进行合作和沟通,这有助于锻炼自己的团队协作能力,了解如何协调各方之间的工作。
代码风格:在项目开发过程中,可以学习借鉴其他成员的代码风格和编写习惯,提高自己的代码质量和可读性。
错误处理:在项目开发过程中难免会遇到各种各样的错误和异常情况,这可以让自己更加熟悉如何进行错误处理和调试技术。
用户体验:在项目开发中需要考虑用户体验,例如界面设计、交互效果等,这有助于让自己更加关注用户需求和体验,提高产品的用户满意度。
总之,通过参与前端开发项目,可以不断提高自己的技术水平和综合能力,为未来的职业发展奠定坚实的基础。
入行三年规划
如果面试官问到前端行业三年规划,可以考虑以下几个方面来回答:
技术深度:在前端领域,技术更新非常快,三年时间大概可以掌握一些比较核心和深入的技术,例如 React 或 Vue 框架、Webpack 构建工具、Node.js 后端开发等。同时还可以尝试学习一些新的技术,例如 WebAssembly、PWA 等,以便跟上前端技术的最新发展。
行业趋势:前端行业的趋势和发展方向也需要关注,例如前端组件化、前后端分离、微前端、GraphQL 等,这些技术和思想都是近年来比较热门的话题,了解并掌握它们可以提高自己的职业竞争力。
团队协作:随着工作经验的增加,可能会逐渐接触到团队协作和项目管理等方面,因此可以考虑学习一些相关的知识和技能,例如敏捷开发、DevOps、代码评审、团队协作工具等,以提高自己与团队合作的效率和质量。
跨界拓展:如果有兴趣或者机会,也可以考虑学习和拓展其他领域的知识和技能,例如设计、产品经理等,以便更好地理解和协作其他团队成员,并为自己未来的职业发展打下更广阔的基础。
总之,前端行业的三年规划需要综合考虑个人兴趣、技术水平、市场需求和行业趋势等多方面因素,制定具体的计划,并不断学习和实践,才能实现自身价值的提升和职业规划的成功。
反问
技术栈Vue
进去是可能会一直写一些简单的业务(刚毕业比较注重基础)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!