javascript 关于赋值、浅拷贝、深拷贝
以下是对关于赋值、浅拷贝、深拷贝的学习
数据类型
说这个话题之前,先扯一下JS的基本数据类型。
大家都知道JS中的数据类型分为:
基本类型:string, number, boolean, null, undefined,symbol(ES6新增)
引用类型:Object,特殊的有Array, Function, Date, Math, RegExp, Error等((Object类)有常规名值对的无序对象{a:1},数组[1,2,3],以及函数等)
那什么是引用类型呢?这又得扯上JS的内存机制了。
JS的内存跟其他的内存差不多,分为堆(heap)和栈(stack)。
- 栈和堆
栈:由系统自动分配,自动回收,效率高,但容量小。
堆:由程序员手动分配内存,并且手动销毁(高级语言如JS中有垃圾自动回收机制),效率不如栈,但容量大。
请注意区分数据结构中所说的堆栈和内存中的堆栈是两回事。 - 基本类型和引用类型分配位置(栈,堆)
JS的基本类型分配在栈中,而因为引用类型大小的不固定,系统将存储该引用类型的地址存在栈中,并赋值给变量本身,而具体的内容存在堆中。所以当访问一个对象的时候,先访问栈中它的地址,然后按照这个地址去堆中找到它的实际内容。例
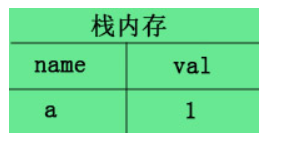
- a.基本类型–名值存储在栈内存中,例如let a=1;
当你b=a复制时,栈内存会新开辟一个内存,例如这样: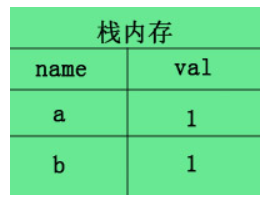
所以当复制的时候,对于基本类型的变量,系统会为新的变量在栈中开辟一个新的空间,赋予相同的值,然后这两个变量就各自独立,毫无牵连。所以当你此时修改a=2,对b并不会造成影响,因为此时的b已自食其力,翅膀硬了,不受a的影响了.
- b.引用数据类型–名存在栈内存中,值存在于堆内存中,但是栈内存会提供一个引用的地址指向堆内存中的值
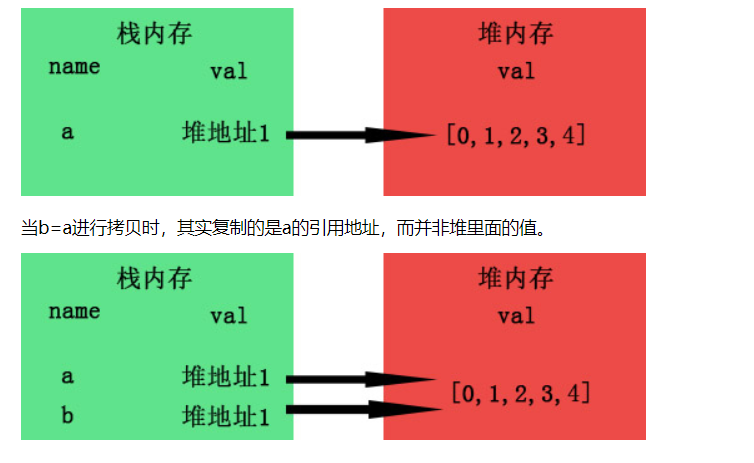
而对于引用类型的变量,新的变量复制的是那个对象在堆中的地址,这两个变量指向的是同一个对象。
例子:简单的引用拷贝(浅拷贝)
var obj = {name: 'Yecao'};
var obj2 = obj;
console.log(obj2.name); // 'Yecao'
obj2.name = 'Claire';
console.log(obj.name); //'Claire'
以上是个很简单的例子,obj2复制了obj之后,两个其实指向的是同一个对象。
而当我们a[0]=1时进行数组修改时,由于a与b指向的是同一个地址,所以自然b也受了影响,这就是所谓的浅拷贝了。
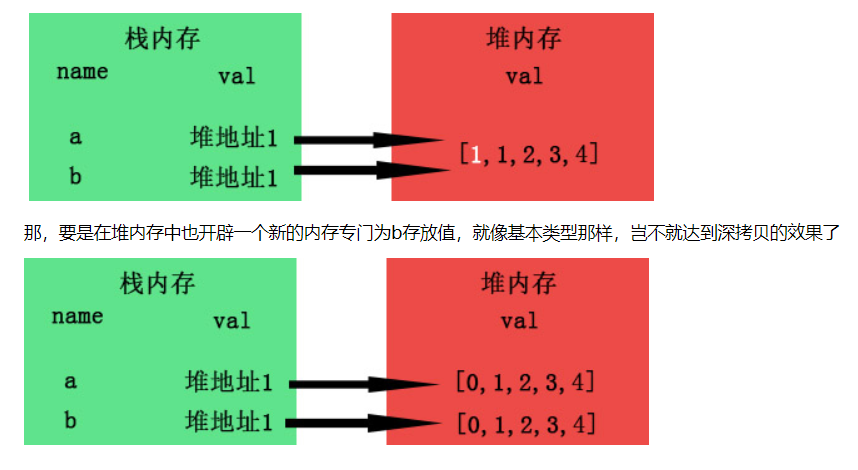
实现简单的深拷贝
这么我们封装一个深拷贝的函数(PS:只是一个基本实现的展示,并非最佳实践)
1 | |
可以看到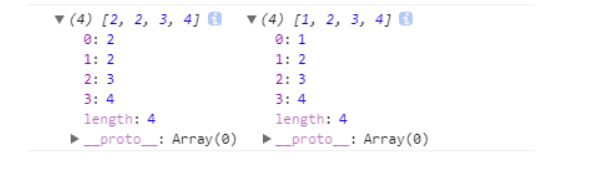
跟之前想象的一样,现在b脱离了a的控制,不再受a影响了。
这里再次强调,深拷贝,是拷贝对象各个层级的属性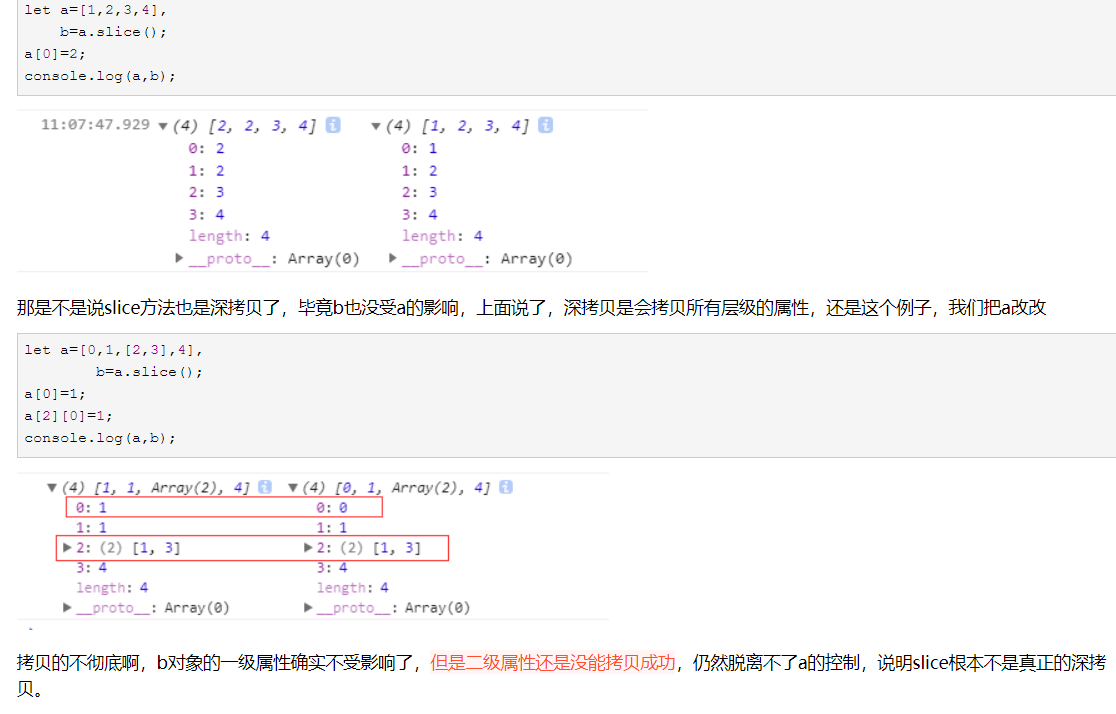
第一层的属性确实深拷贝,拥有了独立的内存,但更深的属性却仍然公用了地址,所以才会造成上面的问题。
同理,concat方法与slice也存在这样的情况,他们都不是真正的深拷贝,这里需要注意。
slice 和 concat
Array 的 slice 和 concat 方法 和 jQuery 中的 extend 复制方法,他们都会复制第一层的值,对于 第一层 的值都是 深拷贝,而到 第二层 的时候 Array 的 slice 和 concat 方法就是 复制引用 ,jQuery 中的 extend 复制方法 则 取决于 你的 第一个参数, 也就是是否进行递归复制。所谓第一层 就是 key 所对应的 value 值是基本数据类型,也就像上面栗子中的name、age,而对于 value 值是引用类型 则为第二层,也就像上面栗子中的 company。
总结
- JS的基本类型不存在浅拷贝还是深拷贝的问题,深拷贝与浅拷贝的概念只存在于引用类型。
- 对于仅仅是复制了引用(地址),换句话说,复制了之后,原来的变量和新的变量指向同一个东西,彼此之间的操作会互相影响,为 浅拷贝。
而如果是在堆中重新分配内存,拥有不同的地址,但是值是一样的,复制后的对象与原来的对象是完全隔离,互不影响,为 深拷贝。 - 深浅拷贝 的主要区别就是:复制的是引用(地址)还是复制的是实例。
参考链接
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!